Drone Project
Skip to the interesting sections!

Introduction
What we did

Materials and Methods
How we did it

Results
What we got
PyStalk is an autonomous surveillance drone, which uses machine learning and computer vision, that can track animals or people when manually prompted to take off and land.
Poaching is recognised as one of the key extinction drivers for endangered species worldwide. With natural biodiversity at risk, new technologies are needed to protect endangered animals.
With 41,415 species acknowledged on the IUCN Red List as endangered, poaching presents a growing threat to Earth’s biodiversity. Poaching is recognised as one of the key extinction drivers for endangered species worldwide. However, traditional methods of combating poachers are no longer enough; new, more efficient methods are required. In this context, the capabilities of artificial intelligence and unmanned aerial vehicles (UAVs) such as drones, to fight poaching efforts will be explored. More specifically, this study used a pre-trained convolutional neural network (CNN) to detect a target autonomously. In this project, the drone camera was used for the detection and tracking of animals and poachers. The objects were detected using a pre-trained TensorFlow object detection model and the drone was accessed remotely using the PyParrot software. All the movement processing and connections between the systems were written by the project team. The results were promising, considering the available time and hardware limitations. The drone motion is not optimal and is relatively slow to react to the movement of the target. However, it can still follow humans at moderate speeds. Thus this project serves as a good proof of concept for a drone that can observe animals.
What we did
How we did it
What we got
Why we got it
What we think about what we got
Who did what
Introduction and Theory
Poaching, which is the illegal hunting, capture or killing of animals, is a global problem: millions of animals from thousands of species are being killed or captured in their native habitats. Elephants, rhinos, and other impressive creatures, as well as smaller and rarer animals like lizards and monkeys, are amongst the many at risk of poaching (Actman, 2019). Poached animals are killed or captured for a variety of reasons, including their commercial values on the black market. Besides being killed for profit, some animals are targeted to prevent them from damaging farms or livestock. Poaching is in some cases the primary reason why a species is at risk of extinction (Meijer et al., 2018).
The large size of animal habitats makes it difficult to control the area with the traditional surveillance methods, such as security guards. Conservationists are, in an effort to protect animals from poaching, beginning to use unmanned aerial vehicles (UAVs) such as drones to surveil habitats, locate poachers, and track animals.
According to Olivares-Mendez et al (2015), an ideal anti-poaching drone would include “autonomous taking-off and following of a predefined position list, tracking animals, detecting poachers faces, tracking and following poachers vehicles and return, via an autonomously-landing scenario, on specific stations in order to recharge the batteries and prepare for the next surveillance flight”.
Within the constraints of this project, we aim to program an autonomous surveillance drone using machine learning and computer vision that can track animals or people when manually prompted to take off and land, called PyStalk.
Computer Vision and Image Understanding
Computer vision can be seen as an attempt to mimic the human visual system. It can be broken down into four main modules as described in Figure 1 (Ciric et al., 2016).
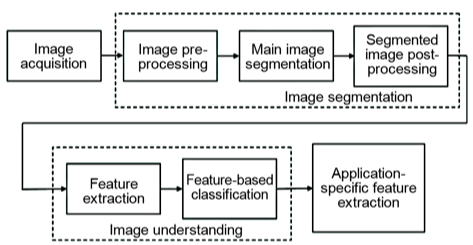
Figure 1: Computer vision block-diagram (Ciric et al., 2016)
Image acquisition is defined as the act of capturing and storing an image. After the image acquisition, the image segmentation focuses on dividing the pixels of a picture into regions or categories. The idea is to group the labelled pixels into connected regions according to their category (Glasbey and Horgan, 1995). This preprocessing is meant to facilitate the image understanding module. Reducing the area of interest and pre-labelling facilitates the analyzing process. The image understanding component is the essential and most challenging part of computer vision and consists of analyzing a scene and recognizing all of the constituent objects.
Two different types of object recognition are distinguishable: generic recognition (or class recognition) and specific object recognition. Generic recognition is defined as generalizing to recognize instances of the same category. Specific object recognition (or instance recognition) differentiates instances within a class of objects (Grauman and Leibe, n.d.).
While computers are able to restore a 3D vision of the real world despite their 2D perception, their image recognition is still considered less efficient than that of a two-year-old child. The key difference between human vision and computer vision lies in the inability of computers to give meaning to an image. Unlike humans who can describe and understand what they see, computers are limited in that regard. They need to be taught what is worth remembering, in order to assign any kind of value to an image. This memory comes in the form of databases with specific labels. These labels act as an explanation of the memories. The issue with recognition can be broken down into several common units. In the case that a computer knows what it is looking for, all it has to do is scan the image for a potential match with the given database. This is known as object detection. The match is generally determined by characteristic feature points and their geometrical alignment stored in the database. Given the myriad of positions an object can adopt, and the possibility of partial occlusion, it becomes clear that generic recognition is already a complex task. For each different potential representation of an object, the computer must be able to categorize them in the same group. Specific object recognition is an even more difficult task: the numerous options of postures and appearances of the same object are unlikely to be stored in a machine’s database (Szeliski, 2011).
In an attempt to increase the object recognition efficiency of computers, computer vision has been enhanced by machine learning. Acting as an artificial brain, neural networks come closer to mimic the human visual system.
Convolutional Neural Network
Recent advancements in computer sciences have seen new and more efficient ways to compute electronic systems. One such advancement is a computer program modeled on the crossed synaptic structure of the brain, Neural Networks (NN). NNs are often used in object classification or, in the context of this project, to identify objects and their position within an image. NNs are usually described in their simplest form as having three principal layers of connected nodes: an input layer, a hidden layer, and an output layer (as illustrated in Figure 2).
Nodes represent a form of artificial neuron denoted by a number between 0 and 1. Each node of one layer is connected to all the nodes of its adjacent layer by a weight, a random number between 0 and 1. Each node receives multiple inputs, makes a weighted sum over them, and returns the corresponding output (Pokharna, 2019). Each layer plays a crucial role in the network: Firstly, the input layer. It contains all the information that needs to be processed. For example, to feed an image into an input layer each pixel of the image would be assigned to individual nodes in the input layer. These values would correspond to a colour gradient and would be normalised before being fed to the network.
Secondly, the hidden layer is a layer of nodes that plays a crucial role in adding complexity to the network. It provides more trainable parameters that allow the network to distinguish itself further from the raw inputs (pixels in our example) and come closer to the desired outputs. More hidden layers have to be added when the task increases in difficulty. Multiple hidden layers add even more trainable parameters and therefore allow the network to make better predictions but require greater computational power.
Lastly, the output layer is a layer that provides the machine analysis of the situation. Each node on the output layer corresponds to a possible outcome. The value assigned to each node corresponds to the confidence level that the machine predicts that outcome.
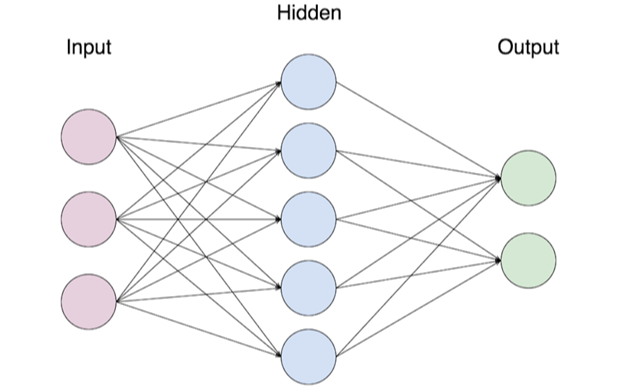
Figure 2: Schematic of a Neural Network.
The first input layer is the point of data entries comprised of numpy arrays of numbers normalised between 0 and 1. This data is then fed through the neural network by multiplying each data point (node) by a weight (connection). This weighted sum comprises a single node of the hidden layer. This layer allows for more complexity in the system. The process is repeated until the output layer. This final layer is tested against the expected output and the weights are modified accordingly. This process is called training the network (TechnoReview, 2019).
Before a NN is able to make accurate predictions it needs to be trained. A large pool of data and their corresponding correct outcomes are fed into the network. The network predicts the outcomes solely based on the input data then compares its prediction with the correct outcome. It evaluates the difference and adjusts its weights accordingly to get more accurate predictions. In doing so, the network changes the values on its weights and nodes and trains itself to identify certain patterns within images. One can appreciate that this entire NN is solely modeled on a weighted sum formula.
Normal NNs work well for basic classifications, however, when more complex tasks are required, they do not provide a sufficiently efficient solution. To combat this, Convolutional Neural Networks (CNN) exist. Unlike NNs, CNNs are applied on volumes: two dimensions of pixel resolution and one for the different colours: red, green, and blue. A one-dimensional filter of resolution smaller than the original image slides along the image. On its path, the dot product between the smaller parts of the image and the filter is computed and recorded. This process is called convolution. Each dot product is a scalar, that forms a “filtered image” as an output. Multiple independent filters are used, each is convolved with the image. In doing so multiple feature maps are created with dimensions smaller than the original image. Like the hidden layers in the NN adding multiple convolutional layers increases the precision and feature extraction of the network.
There are a few additional and important features in the context of neural networks. One of these is the use of biases. A bias is an extra value added to a node. Biases can also be trained in combinations with weights. It helps the model adapt more efficiently to its training. Additionally, during training, it is possible that a node is reduced to zero. In this case, no amount of learning (or multiplying by numbers) will change this node. In effect, “killing off” a part of the network.
Object Tracking and Autonomous Drone Navigation
Taking one step closer towards human vision, object tracking involves the analysis and interpretation of videos which allow computers to upgrade their representation of the real world. The task of object tracking is the action of finding the position of an object in every frame. The efficiency of object tracking is dependent on the choice of object representation and on how suitable the object tracking method is. As illustrated in Figure 3, object tracking relies on three main techniques: point tracking, kernel tracking and silhouette tracking (Ågren, 2017). This project focussed on kernel tracking, using a quadrilateral shape to determine primitive object region.
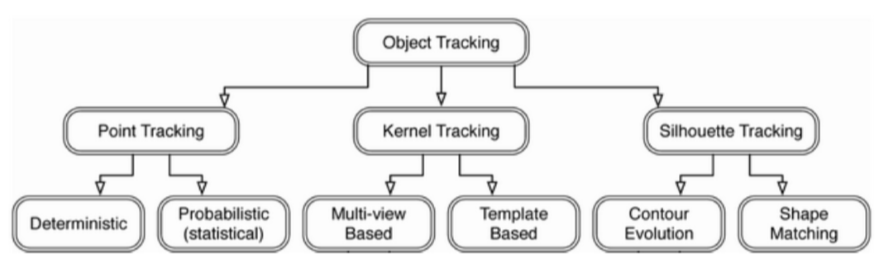
Figure 3: Object Tracking block-diagram (Ågren, 2017).
The point tracking approach modelizes the detected objects as points and tracks them by evaluating their position and motion. Kernel tracking relies on the computation of the motion of the object represented as primitive object region (frame). The tracking marker is a simple geometric shape enclosing the object. Kernel is referring to the appearance and shape of the object. Silhouette tracking uses kernel tracking to determine the region that matches the model, in the frame.
When implemented in a mobile device (i.e. a drone), object tracking enables a real-time autonomous navigation capacity. Assuming the consistency of object identification tracking, the main challenge of autonomous navigation is obstacle avoidance, especially in dynamic environments (Ess, et al., 2010). Tracking by detection associates the object detection results with integral trajectories to design a flying path (Lui, et al., 2014). This project will use a 2D image position and will assume that by following the target, obstacle avoidance is guaranteed.
Materials and Methods
Drone Model & Features
The project was conducted with a Bebop2 drone from the Parrot company. Bebop2 has a 25 minutes long flying autonomy and weighs 500 grams. The drone has two flying modes: the videography mode and the sports mode. The camera is adapted for both indoor and outdoor environment ("Parrot Bebop 2", 2019).
Tutorials
The PyStalk project can be reproduced by the tutorials stored on the following GitHub repository under the ‘Tutorial’ folder.
5 tutorials are available:
The “short python intro” can be used to get the basics of Python programming language.
The “intro_to_neural_nets” provides a general introduction to neural networks. The theory is applied to a handwritten digit (MNIST) recognition.
The “Using Convolutional Neural Networks to classify dogs and cats” provides a general way to use convolutional neural networks to classify images.
The “TF_model_tutorial” can be used as an instruction guide to install all the packages needed to run the TensorFlow model ssdlite_mobilenet_v2_coco.
The “Getting ready with pyparrot_modified” provides an installation guide for all the libraries needed for the drone connectivity and the drone motion.
Data Acquisition and Processing
In this project, two data-sets were created for the purpose of training the CNN. The first data-set is comprised of pictures of humans, while the second data-set consists of images of a dog.
The data-sets were obtained in two ways: from images and from footage recorded on the drone. The images and videos were taken from multiple angles and heights in order to form a comprehensive training set for the CNN.
For the image-based data-set, images were resized to a lower quality to reduce the processing requirements for the neural network. To do this, Image Resizer for Windows was used to set the picture quality to 827 x 480.
For the video-based data-set, the video was split into images using VLC media player. To do this, the settings of VLC had to be changed. Within Tools>Preferences>Show settings: all> Video>Filters>Scene filter, the image format and size was set to .jpg 827 x 480. The recording ratio, which sets the amount of frames between each extracted image, was set to 24; this means that an image was extracted every 24 frames.
These image-sets then needed to be bounded using labelImg. Bounding is setting a rectangular box around the dog or person in the image; this creates a set of x, y coordinates that inform the CNN where the object of interest is in the picture. The images were randomly allocated to test and train folders for the neural network.
The bounded images then were converted into test and train .csv files - these are spreadsheets listing the coordinates of the bounding boxes in the images. From these .csv files, .tfrecords were made. A TensorFlow TFRecord is a binary storage format that is optimised for data-set storage, integration and pre-processing. For these format conversions, a python script was created to automate this. The .tfrecords are the files used to train the tensorflow object detector
Movement Control
Roll, Pitch, Yaw, and Thrust were the four parameters used in this project to control the movement of the drone. Figure 4 describes these motions in greater detail.
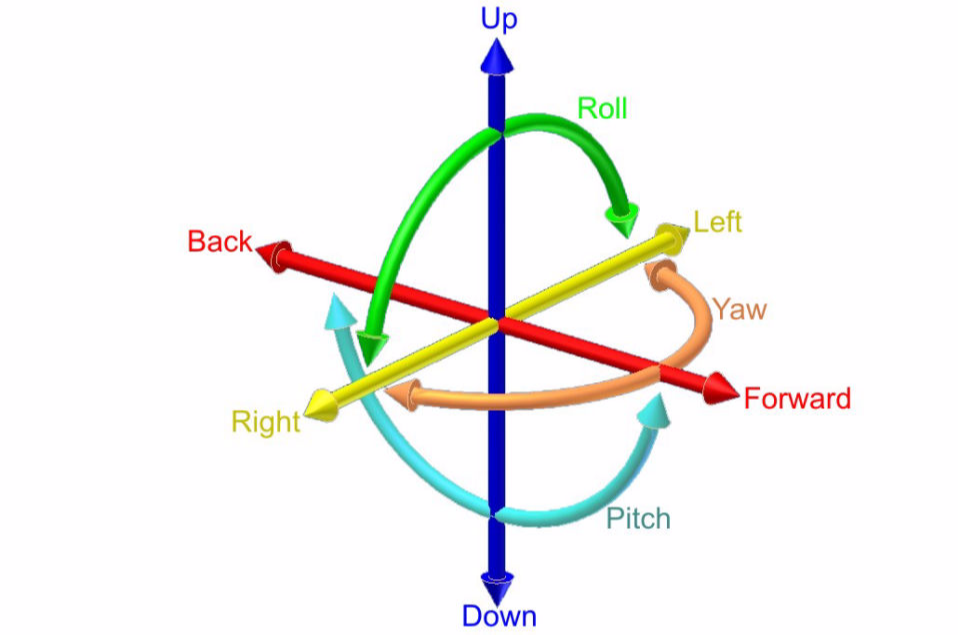
Figure 4: Schematic representation of the drone motion commands (Emissary Drones, 2019)
The change in yaw determines the rotation of the drone and allows it to track an object that is moving left or right. Roll allows the drone to move left or right. This allows the same tracking capability as yaw by moving the drone rather than rotating it. Pitch allows the drone to move forwards or backwards and therefore regulate its distance to the target. The vertical motion is controlled by the thrust of the propellers. This project implemented a fixed vertical motion. Manually the drone height could be adjusted.
Box Smoothing
Given the unreliability of the object recognition and the potential occlusion of objects (e.g. vegetation), the tracking is still experimental. The possible issues laid in a lack of object detection in some frames of the video. In response to this, a “smoothened box” was implemented. This box solves the issues by taking a weighted average of the location of the detected boxes of the last 30 frames. In doing so, the detection is made smoother and a possible sudden jump, causing an acceleration of the drone, is everted. The number of frames considered for the weighted average is modifiable. This particular implementation allowed the drone to compensate for the lack of boxes over a period of about one second (frames come in at a rate of 25/second).
Currently, the frames are weighted as n^5, where n is the position of the frame. This means that the last frames weigh much more than the first frames. This is a good solution however, it is likely that an exponential weighting (e^n) would have been more efficient in updating smoothened boxes faster. This was not experimentally confirmed however, it remains highly probable. Due to the delay with the WIFI transmissions, the polynomial weighting is deemed to be less efficient as it causes an additional delay when objects are moving quickly.
The second computation done by the box smoothing function selects one of the potentially multiple recognized objects for the tracking. This is done by choosing the box with the highest recognition certainty in the first frame. In every subsequent frame, the computation is implemented to check which of the boxes around the recognized objects is closest to the smoothened box. This way, a sort of ‘understanding’ of object permanence can be achieved. This is important to avoid the drone flying towards other animals that are not supposed to be tracked. One current issue is that the box switches away from one target very quickly when it is not recognized anymore. Instead, it finds another target since it assumes that the object moves very quickly.
Rotational vs Fixed Tracking
The drone can operate on two different tracking modes; rotational and fixed. If rotational tracking is activated yaw and pitch are used and the roll stays constant. This tracking is much more dynamic and far more adept at tracking in open areas. The downside is that as GPS stabilization is not activated the drone tends to drift to the side. If fixed tracking is activated, the rotation is set on a given angle and the drone moves by only using roll and pitch. The issue of drifting is no longer present as the left/right motion is relative to the object. In other words, if the object doesn’t move, the drone won’t move either. That said, the drone has a tendency to lose the object that it is tracking despite the countermeasures in place.
Pitch
The drone motion is implemented so that the drone will constantly regulate its position according to the distance to the object. This distance is specified by a “desired box size”. The latter represents the area on the screen that the user would like the tracked object to cover. This means that the drone will try to move further away from the object if it notices that more than the desired percentage of the screen is covered and vice versa. This desired distance is defined by two boxes (which are displayed in the GUI in light blue). One box is the maximum amount of the screen that should be covered and the other box represents the minimum amount of screen that should be covered. Consequently, the drone will adjust its distance so that the size of the object remains between those two boxes.
The computation for this is not trivial and is currently expressed as the set_distance() function in the Movement_processing code file:
def set_distance(self):
if (self.box_size > 0):
if self.box_size > self.max_distance:
self.pitch = (self.box_size - self.max_distance) * -3
elif self.box_size < self.min_distance:
self.pitch = (self.box_size - self.min_distance) * -3
else:
self.pitch = 0
The key idea is that if the box of the object recognition is bigger than the maximal box size, the drone adjusts its distance accordingly: (current box size/maximal box size) * -3.
Inversely, if the current box size is smaller than the minimal box size, the drone will move closer to the target :(minimal box size/current box size) * 3.
This nonlinear computation is favored over a general linear approach such as: current box size - maximal box size) * 3. This is due to the fact that the change in box size on the last few meters is much bigger than at a high distance. At a distance of one metre, a person covers about half the screen whereas they almost cover the full screen half a metre closer. In comparison, there is no noticeable change between a box size of 100 metres or 110 metres away. Despite that, this formula is certainly not ideal. This is because it scales up drastically at big distances. Therefore dangerous situations can occur when the drone starts tracking from far away. In this case, the drone accelerates to very high speeds and will not stop in time due to its input delays.
Camera tilt
The command for controlling camera tilt is very efficient in this current version. Despite it being relatively slow, it still keeps up with most of the motions of the drone. Increasing the sensitivity of the tilt was explored, but a tendency to overshoot the target rather than settle on its position was noticed. A helpful addition would have been to also make this function a polynomial. In doing so, the tilt should react faster and not overshoot the target.
Rotation
The rotation is computed in the same way as the camera tilt and shows the same functionality. The only difference is that the rotation is sometimes unable to keep up with the objects. Therefore the same recommendation holds. It is advised to investigate a polynomial change in velocity.
Roll
The roll command is very difficult to control. It is more difficult for the roll to keep up with the object’s movement as well as the other motion commands. It was observed that if it is set on a higher sensitivity, it overshoots very easily and if it is set on a lower sensitivity it almost always loses the object. It is also assumed that a polynomial/exponential translation would be beneficial, yet it seems that rotational tracking is (at least in open areas) much easier to implement.
Results
This video is an introduction on how to run and use PyStalk, which explains the GUI and the available settings.
This video shows the final result of our project; the drone tracking a person in an open field. It shows the limitations in speed and accuracy as well as the quality of recognition.
Discussion
As seen in the videos showcasing the functioning of the drone, the drone can perform basic maneuvers in order to keep the target in frame. These include, moving forwards, backwards, to the sides, as well as adjusting the tilt of the camera. The drone correctly responds to most situations that require these operations, yet the drone’s functionality still has many flaws.
The main issue with the current version of PyStalk is that there is a high input delay. This makes it impossible to track targets that move very quickly and change directions. In large part, this could be fixed by running the network on the drone itself rather than on a computer. The limiting part is not the neural network but rather the video display on the computer. With an efficient neural network such as pytorch’s YOLOv3, or one of tensorflow’s mobile object detectors, such an endeavour should be possible, without draining the drone’s battery or causing it to overheat. This would almost completely solve the issues regarding the input delays. This is because the video transmission via WIFI would no longer be necessary and therefore allow for instant transmission. Additionally, it would allow the drone to operate at any distance, rather than being limited to a 2-kilometre range around the computer operating it.
Another issue that still has to be reviewed is the configuration of the hyperparameters; even though all algorithms prove to be working as intended, the specific values with which the movement is computed still need tweaking. To give an example, when the drone is in the ‘Fixed Tracking’ mode, it will overshoot slightly from left to right and vice versa (rather than stopping in front of the object). Whereas it is too slow in the ‘Rotation Tracking’ mode where it can easily lose it’s target (see minute 0:30 in the “tracking showcase” video.) This could be greatly improved by computing values polynomially/exponentially rather than linearly. For instance, the current formula to set the rotation speed is:
(centre of screen - position of object)*40= rotation velocity # 40 = scaling factor
This would be fixed by making it polynomial, e.g.:
(centre of screen - position of object)^2
Which makes the drone rotate very quickly when the object is at the edge of the screen but very slowly when it is central. This should be employed for all (or most) parts of the movement control since the same issues are encountered when trying to stay at the correct distance and tilting the camera.
One of the most successful implementations of the PyStalk project is its capacity to follow one single target, despite recognizing multiple targets. This is due to the box smoothing algorithm mentioned above. One can easily observe the drone capacity to recognize multiple people (multiple red boxes in the video) and still following the initial target.
Conclusion and Future Ideas
With respect to the available resources and time, this project is considered a success, given that PyStalk can make a drone follow humans autonomously at moderate speeds. Even though the general outcome is positive, there are still multiple aspects that can be improved upon.
The installation tutorials are currently written for bash language, restraining the target audience to Linux and macOS computers. Moreover, the DroneVisionGUI code file of the PyParrot project cannot be used by macOS computers, since the VLC window is not allowed to open (this issue is specific to macOS; VLC has to be opened from the main thread). PyParrot provides a second vision server option (ffpmeg) which saves the picture and creates a video retrospectively via the VisionServer and DroneVision code files. However, it appears that a bug causes part of the frames to be unusable. Therefore, the vision module is only accessible for Linux operating systems via the VLC option. One of PyStalk future projects could be to expand its operating system compatibility. To achieve this, it is planned to use docker in the future.
Beyond mediating these compatibility issues, this project strives to create an object detection network. This could easily be achieved since the target objects are very specific, and thus a more specific AI could increase its efficiency. This improvement could provide the basis for an entirely separate project as it requires the collection of a particular dataset and the designing a convolutional neural network which is non-trivial. Since most poaching occurs at night, a more effective way of identifying animals would be using thermal vision cameras. This would also greatly improve the certainty in object detection since it is much easier to pick up on a change in temperature than RGB colours. This is useful because animals are one of the few objects with raised temperature compared to the environment whereas they are evolved to blend in with the environment’s colours. Unfortunately, drones equipped with such cameras are not available due to monetary project constraints.
The current linear computations used to convert the output from the CNN to the movement of the drone have shown to be unsuccessful when tracking fast moving targets. As proposed in the movement control section, these could be converted to exponential or polynomial control computations. This would allow for very fast movement in extreme situations (for example, if the target is near the edge of the screen). Additionally, by using tensorflow’s mobile nets (e.g. MobileNet v2) the computer vision part could be moved to the drone, allowing it to react much faster. It is expected that these two attainable improvements would lead to a significant increase in functionality.
References
Actman, J. (2019). Poaching animals, explained. Retrieved from https://www.nationalgeographic.com/animals/reference/poaching-animals/
Ågren, S. (2017). Object tracking methods and their areas of application: A meta-analysis: A thorough review and summary of commonly used object tracking methods.
Ciric, I., Cojbasic, Z., Ristic-Durrant, D., Nikolic, V., Ciric, M., Simonovic, M. and Pavlovic, I. (2016). Thermal vision based intelligent system for human detection and tracking in mobile robot control system. Thermal Science, 20(suppl. 5), pp.1553-1559.
Emissary Drones. (2019). What is Pitch, Roll and Yaw ?. Retrieved from https://emissarydrones.com/what-is-roll-pitch-and-yaw
Ess, A., Schindler, K., Leibe, B., & Van Gool, L. (2010). Object detection and tracking for autonomous navigation in dynamic environments. The International Journal of Robotics Research, 29(14), 1707-1725.
Glasbey, C. and Horgan, G. (1995). Image analysis for the biological sciences. Chichester: John Wiley & Sons, Chapter 4: Segmentation.
Grauman, K. and Leibe, B. (n.d.). Visual Object Recognition - Synthesis Lectures on Computer Vision # 1.
Liu, X., Tao, D., Song, M., Zhang, L., Bu, J., & Chen, C. (2014). Learning to track multiple targets. IEEE transactions on neural networks and learning systems, 26(5), 1060-1073.
Meijer, W.; Scheer, S.; Whan, E.; Yang, C. and Kritski, E. (2018). Demand under the Ban – China Ivory Consumption Research Post-ban 2018. TRAFFIC and WWF, Beijing, China.
Olivares-Mendez, M. A., Fu, C., Ludivig, P., Bissyandé, T. F., Kannan, S., Zurad, M., . . . Campoy, P. (2015). Towards an Autonomous Vision-Based Unmanned Aerial System against Wildlife Poachers. Sensors, 15(12), 31362-31391.
Parrot Bebop 2. (2019). Retrieved from https://www.parrot.com/nl/en/drones/parrot-bebop-2
Pokharna, H. (2019). The best explanation of Convolutional Neural Networks on the Internet!. Retrieved from https://medium.com/technologymadeeasy/the-best-explanation-of-convolutional-neural-networks- on-the-internet-fbb8b1ad5df8.
Szeliski, R. (2011). Computer vision - Algorithms and Applications. New York: Springer, pp.575-640.
TechnoReview. (2019). Artificial Neural Network : Beginning of the AI revolution. Retrieved from https://hackernoon.com/artificial-neural-network-a843ff870338.
Appendix
| Practical Work | |
|---|---|
| Data acquistion and processing | Fenora and Felix |
| Installation (libraries, dependencies…) | Felix, Szymon, Timour and Siane |
| Motion project
| Felix, Szymon and Siane |
| Neural network project
| Timour |
| Project combination
| Felix |
| Testing of general project (tracking with drone)
| Everyone |
| Reporting | |
| Abstract | Szymon and Fenora |
| Introduction | Timour, Fenora and Siane |
| Material and Methods | Fenora, Szymon and Siane |
| Tutorials (Jupyter notebooks) | Felix, Szymon, Siane and Timour |
| Results | Fenora and Felix |
| Discussion | Szymon and Felix |
| Conclusion and Future Ideas | Siane, Szymon and Felix |
| Formatting | Everyone |
| Website | Fenora |
| GitHub Repository Editing | Felix |
| Appendix | Siane |
| NAME | ID | @ |
|---|---|---|
| Felix Quinque | i6166368 | f.quinque@student.maastrichtuniversity.nl |
| Szymon Fonau | i6161129 | s.fonau@student.maastrichtuniversity.nl |
| Fenora Mc Kiernan | i6156417 | f.mckiernan@student.maastrichtuniversity.nl |
| Timour Javar Magnier | i6175968 | t.javarmagnier@student.maastrichtuniversity.nl |
| Siane Lemoine | i6159295 | ag.lemoine@student.maastrichtuniversity.nl |


